基础知识:
- 比特(bit):信息量最小的单位。二进制数字中的位(0与1),如二进制数1010就是4比特。通常以小写
b来表示。 - 字节(byte):计算机存储容量的计量单位。通常情况下,1个字节有8比特,即1 byte=8 bit。2^8^ = 256,代表1字节可表示最大的整数是256。通常以大写
B来表示。 - 字符:包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。一个字符代表一个符号,存储的大小依据系统和编码而定。
ASCII编码
基础包含了大小写英文字母,数字和一些符号,总共127个字符。
| 二进制 | 十进制 | 缩写/字符 | 解释 |
|---|---|---|---|
| 0000 0000 | 0 | NUL(null) | 空字符 |
| 0000 0001 | 1 | SOH(start of headline) | 标题开始 |
| 0000 0010 | 2 | STX (start of text) | 正文开始 |
| 0000 0011 | 3 | ETX (end of text) | 正文结束 |
| 0000 0100 | 4 | EOT (end of transmission) | 传输结束 |
| 0000 0101 | 5 | ENQ (enquiry) | 请求 |
| 0000 0110 | 6 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 7 | BEL (bell) | 响铃 |
| 0000 1000 | 8 | BS (backspace) | 退格 |
| 0000 1001 | 9 | HT (horizontal tab) | 水平制表符 |
| 0000 1010 | 10 | LF (NL line feed, new line) | 换行键 |
| 0000 1011 | 11 | VT (vertical tab) | 垂直制表符 |
| 0000 1100 | 12 | FF (NP form feed, new page) | 换页键 |
| 0000 1101 | 13 | CR (carriage return) | 回车键 |
| 0000 1110 | 14 | SO (shift out) | 不用切换 |
| 0000 1111 | 15 | SI (shift in) | 启用切换 |
| 0001 0000 | 16 | DLE (data link escape) | 数据链路转义 |
| 0001 0001 | 17 | DC1 (device control 1) | 设备控制1 |
| 0001 0010 | 18 | DC2 (device control 2) | 设备控制2 |
| 0001 0011 | 19 | DC3 (device control 3) | 设备控制3 |
| 0001 0100 | 20 | DC4 (device control 4) | 设备控制4 |
| 0001 0101 | 21 | NAK (negative acknowledge) | 拒绝接收 |
| 0001 0110 | 22 | SYN (synchronous idle) | 同步空闲 |
| 0001 0111 | 23 | ETB (end of trans. block) | 结束传输块 |
| 0001 1000 | 24 | CAN (cancel) | 取消 |
| 0001 1001 | 25 | EM (end of medium) | 媒介结束 |
| 0001 1010 | 26 | SUB (substitute) | 代替 |
| 0001 1011 | 27 | ESC (escape) | 换码(溢出) |
| 0001 1100 | 28 | FS (file separator) | 文件分隔符 |
| 0001 1101 | 29 | GS (group separator) | 分组符 |
| 0001 1110 | 30 | RS (record separator) | 记录分隔符 |
| 0001 1111 | 31 | US (unit separator) | 单元分隔符 |
| 0010 0000 | 32 | (space) | 空格 |
| 0010 0001 | 33 | ! | 叹号 |
| 0010 0010 | 34 | " | 双引号 |
| 0010 0011 | 35 | # | 井号 |
| 0010 0100 | 36 | $ | 美元符 |
| 0010 0101 | 37 | % | 百分号 |
| 0010 0110 | 38 | & | 和号 |
| 0010 0111 | 39 | ' | 闭单引号 |
| 0010 1000 | 40 | ( | 开括号 |
| 0010 1001 | 41 | ) | 闭括号 |
| 0010 1010 | 42 | * | 星号 |
| 0010 1011 | 43 | + | 加号 |
| 0010 1100 | 44 | , | 逗号 |
| 0010 1101 | 45 | - | 减号/破折号 |
| 0010 1110 | 46 | . | 句号 |
| 0010 1111 | 47 | / | 斜杠 |
| 0011 0000 | 48 | 0 | 字符0 |
| 0011 0001 | 49 | 1 | 字符1 |
| 0011 0010 | 50 | 2 | 字符2 |
| 0011 0011 | 51 | 3 | 字符3 |
| 0011 0100 | 52 | 4 | 字符4 |
| 0011 0101 | 53 | 5 | 字符5 |
| 0011 0110 | 54 | 6 | 字符6 |
| 0011 0111 | 55 | 7 | 字符7 |
| 0011 1000 | 56 | 8 | 字符8 |
| 0011 1001 | 57 | 9 | 字符9 |
| 0011 1010 | 58 | : | 冒号 |
| 0011 1011 | 59 | ; | 分号 |
| 0011 1100 | 60 | < | 小于 |
| 0011 1101 | 61 | = | 等号 |
| 0011 1110 | 62 | > | 大于 |
| 0011 1111 | 63 | ? | 问号 |
| 0100 0000 | 64 | @ | 电子邮件符号 |
| 0100 0001 | 65 | A | 大写字母A |
| 0100 0010 | 66 | B | 大写字母B |
| 0100 0011 | 67 | C | 大写字母C |
| 0100 0100 | 68 | D | 大写字母D |
| 0100 0101 | 69 | E | 大写字母E |
| 0100 0110 | 70 | F | 大写字母F |
| 0100 0111 | 71 | G | 大写字母G |
| 0100 1000 | 72 | H | 大写字母H |
| 0100 1001 | 73 | I | 大写字母I |
| 01001010 | 74 | J | 大写字母J |
| 0100 1011 | 75 | K | 大写字母K |
| 0100 1100 | 76 | L | 大写字母L |
| 0100 1101 | 77 | M | 大写字母M |
| 0100 1110 | 78 | N | 大写字母N |
| 0100 1111 | 79 | O | 大写字母O |
| 0101 0000 | 80 | P | 大写字母P |
| 0101 0001 | 81 | Q | 大写字母Q |
| 0101 0010 | 82 | R | 大写字母R |
| 0101 0011 | 83 | S | 大写字母S |
| 0101 0100 | 84 | T | 大写字母T |
| 0101 0101 | 85 | U | 大写字母U |
| 0101 0110 | 86 | V | 大写字母V |
| 0101 0111 | 87 | W | 大写字母W |
| 0101 1000 | 88 | X | 大写字母X |
| 0101 1001 | 89 | Y | 大写字母Y |
| 0101 1010 | 90 | Z | 大写字母Z |
| 0101 1011 | 91 | [ | 开方括号 |
| 0101 1100 | 92 | \ | 反斜杠 |
| 0101 1101 | 93 | ] | 闭方括号 |
| 0101 1110 | 94 | ^ | 脱字符 |
| 0101 1111 | 95 | _ | 下划线 |
| 0110 0000 | 96 | ` | 开单引号 |
| 0110 0001 | 97 | a | 小写字母a |
| 0110 0010 | 98 | b | 小写字母b |
| 0110 0011 | 99 | c | 小写字母c |
| 0110 0100 | 100 | d | 小写字母d |
| 0110 0101 | 101 | e | 小写字母e |
| 0110 0110 | 102 | f | 小写字母f |
| 0110 0111 | 103 | g | 小写字母g |
| 0110 1000 | 104 | h | 小写字母h |
| 0110 1001 | 105 | i | 小写字母i |
| 0110 1010 | 106 | j | 小写字母j |
| 0110 1011 | 107 | k | 小写字母k |
| 0110 1100 | 108 | l | 小写字母l |
| 0110 1101 | 109 | m | 小写字母m |
| 0110 1110 | 110 | n | 小写字母n |
| 0110 1111 | 111 | o | 小写字母o |
| 0111 0000 | 112 | p | 小写字母p |
| 0111 0001 | 113 | q | 小写字母q |
| 0111 0010 | 114 | r | 小写字母r |
| 0111 0011 | 115 | s | 小写字母s |
| 0111 0100 | 116 | t | 小写字母t |
| 0111 0101 | 117 | u | 小写字母u |
| 0111 0110 | 118 | v | 小写字母v |
| 0111 0111 | 119 | w | 小写字母w |
| 0111 1000 | 120 | x | 小写字母x |
| 0111 1001 | 121 | y | 小写字母y |
| 0111 1010 | 122 | z | 小写字母z |
| 0111 1011 | 123 | { | 开花括号 |
| 0111 1100 | 124 | | | 垂线 |
| 0111 1101 | 125 | } | 闭花括号 |
| 0111 1110 | 126 | ~ | 波浪号 |
| 0111 1111 | 127 | DEL (delete) | 删除 |
Unicode编码
涵括了所有语言。一般字符为2个字节,偏僻字符,一般为4个字节。现代操作系统和大多数编程语言都直接支持Unicode。
为了和ASCII码兼容,Unicode编码的前256个字符和ASCII码完全相同,即原本单字节的ASCII码字符,转换成Unicode码,只需在高位补充0即可。
UTF-8编码
把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
UTF-8编码下的英文字符为1个字节,与ASCII编码一样。所以,在只输入英文字符的时候,ASCII编码实际上可以被看成是UTF-8编码的一部分。只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
同时,又比Unicode编码节省存储空间。
Unicode与UTF8的转换规则
| 编码号 | Unicode | UTF8 |
|---|---|---|
| 0~127 | 0000 - 007F | 0xxxxxxx |
| 128~2047 | 0080 - 07FF | 110xxxxx 10xxxxxx |
| 2048~65535 | 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
UTF-8的编码规则:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
总结
-
现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
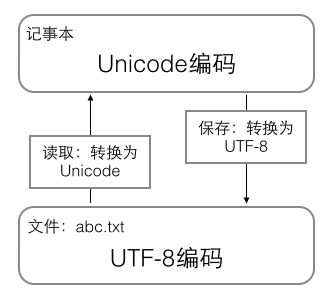
-
在操作字符串时,我们经常遇到
str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。 -
==在网络传输或者存储在磁盘的字节流,数据均是bytes==。
-
需要在客户端显示字符时需要decode()解码
- 当bytes中包含无法完全解码的字节或只含有一小部分无效字节,是会报错。所以可以传入参数
error='ignore'
>>> b'\xe4\xb8\xad\xff'.decode('utf-8') Traceback (most recent call last): ... UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte >>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore') '中' - 当bytes中包含无法完全解码的字节或只含有一小部分无效字节,是会报错。所以可以传入参数
-
需要进行网络传输或者存储时需要encode()编码
>>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87'
-
-
在python3中字符串是以Unicode编码的,并且对
bytes类型的数据用带b前缀的单引号或双引号表示:x = b'ABC'在
bytes中,无法显示为ASCII字符的字节,用\x##显示。 -
len()函数应用在
str字符串时,代表的是包含多少个字符。应用在bytes时,代表多少个字节数。(在ascii码中两者结果一样)
There are 0 comments